Why JSEcoin?
Why JSEcoin?
Traditional cryptocurrencies were not designed for mainstream adoption or web integration. The JSEcoin project is built from scratch to provide solutions to the following issues:
Environmental Impact - PoW mining of traditional cryptocurrencies uses a huge amount of electrical power. JSEcoin is mined using surplus CPU resources reducing the environmental impact of cryptocurrency adoption.
Consumer Friendly - Our hybrid system makes it easy for non-technical users to setup an account, mine currency, make transactions and use cryptocurrency. We provide a safe, simple and intuitive platform for our users.
Built For The Web - We believe cryptocurrency should be web-based. Our system is mined by webmasters and self-miners using a web browser. The online platform provides a web-based point of entry to the JSEcoin network.
WEBSITE MONETIZATION WITH BLOCKCHAIN
BLOCKCHAIN | AD-TECH | ENTERPRISE | E-COMMERCE
Read the Whitepaper- Loading
JSE Closing Down 21st April 2020
Under the current economic environment it has not been possible to raise the funding required to continue the JSE project.
Since 2017 the team has developed and built the network and front-end platforms to bridge web and blockchain technologies. In hindsight we left it too late to raise ICO funds and the project was always bootstrapped. Undeterred we used what little funds we had to the best of our abilities to build out the JSE platform, app and network. The markets for cryptocurrencies have declined since the end of 2017 and this has had a very negative impact on the liquidity and token economics. Organic growth and token demand have slowed significantly making our metrics less desirable to investors. With the Covid-19 pandemic hitting all markets and VC investment our chances of raising are now unrealistic.
The platform will be shut down on the 21st April 2020, at this time a snapshot will be taken of the ledger and published on the website. Remaining funds after liquidation and server costs will be used to continue the buy back programme on LATOKEN exchange which seems the fairest way to reimburse stakeholders. Anyone looking to trade tokens on exchange should withdraw funds to the ERC20 token (which will remain in use) before the date above.
The code-base will remain on Github and the existing ledger json files will be published on this website once they have been finalised.
I hope that in the future someone will continue the work we started and fork the project continuing the existing ledger. Cryptocurrency is the future and the current economic crisis and bail out plans only highlight the need to separate money from state. As a community we need an environmentally friendly alternative to traditional proof-of-work systems.
I would like to thank everyone who contributed to the project. Developers, investors, community members, miners and website publishers. I have been lucky enough to work with some amazing people over the last three years and wish them the best for whatever the future brings. I apologise to everyone who invested time, money and resources into the project who believed, like I did, in what we were doing.
Web Browser Mining
Anyone with a web browser or website can now mine cryptocurrency. Block rewards distributed to real users across the globe.
Ad Exchange
A transparent market place for the purchase and sale of digital marketing space for banner and text advertising.
Merchant Tools
Accept cryptocurrency payments online with simple to setup "Buy with crypto" buttons.
Enterprise Solutions
Enterprise grade API's for bot detection and side chain validations.
Blockchain
Immutable Chronologically Ordered Data
Blockchain technology provides a secure, shared database of unchangeable data. While the concept is simple, we are still only starting to see the use of cases for immutable data emerging. The JSE project has been building on top of blockchain and web technologies to enable website owners to monetize their content.
Blockchain’s are mined using a mathematical calculation on the data in each block. For traditional cryptocurrencies this is competed over by huge server farms. The bitcoin network currently consumes more energy than Switzerland*. The JSE team developed a tool that carries out the same hashing algorithm in a normal web browser without disturbing user experience. Hash calculations are sent back to the nodes which form the network and are used to finalise and secure each block. This gives the project a distinct advantage in cost savings as the network is run using surplus resources.


Ad-Tech
A digital ad-exchange using cryptocurrency micropayments
The JSE ad-exchange provides a transparent marketplace for trading digital advertising placements such as banners and inText ads. Website owners can place advertising code on their website to display ads which are then purchased by advertisers and media buyers using the self-serve platform. Advertising campaigns can be optimised by country, device, browser, siteID, publisherID to provide the best return on investment for our clients.
Publishers have options for auto-ads, custom banners, in-text ads as well as full control over the advertisers that are allowed to purchase inventory on their site.
The JSE token is used as the medium of exchange via micropayments on the JSE blockchain.
To attract website owners to our platform we have developed further tools such as a captcha solution, wordpress plugins and a developer API.
Enterprise
Developing solutions for business
Energy and cost savings make the JSE blockchain very competitive for 3rd party integrations. The team have developed a side-chain API which allows businesses easy access to the benefits of blockchain.
Our internal bot-detection and fraud prevention tools are available as a 3rd party API. The network receives high volumes of traffic through the browser mining and captcha solutions which provides data on suspicious connections and bot networks. This data is anonymously analysed using machine learning algorithms to provide risk assessments.
Our team have front-end and back-end developers who are available to customise solutions and help integrate blockchain solutions that add value to clients business systems.


E-Commerce
Accepting cryptocurrency payments online
In the future we believe that cryptocurrency transactions will be adopted by a mainstream user base to send funds much like we send emails today. Every year more trade is being done online and e-commerce stores and websites will want a way to accept cryptocurrency payments.
The JSE merchant tools provide a simple “Buy with Crypto” button that can be placed alongside other payment gateways to accept cryptocurrency payments. Shopping cart plug-ins are also available for stores to quickly setup crypto payments and be future ready.
The payment processing industry provides an exceptional opportunity to add value and benefit from the growth in cryptocurrency adoption.
ENVIRONMENTAL IMPACT OF CRYPTOCURRENCY
TRADITIONAL CRYPTOCURRENCIES USE MORE POWER THAN SMALL COUNTRIES TO OPERATE THEIR NETWORKS
Every other industry across the globe is moving towards greener solutions that mitigate the risk of climate change and global warming. Sooner rather than later blockchain technology needs to follow suit. There is simply no need to consume the vast amounts of electrical power that traditional cryptocurrency networks waste.
JSEcoin is mined using surplus CPU resources which would be otherwise wasted. Browser mining has a huge environmental and cost advantage over existing cryptocurrency networks. There is an opportunity to make a real difference with web based cryptocurrency mining.
Current mining practices are not sustainable or justifiable in terms of energy consumption - we feel browser mining provides a solution. Whether it’s our project that breaks through with it or someone else’s, this is the direction the industry is going in and we have the first mover advantage.

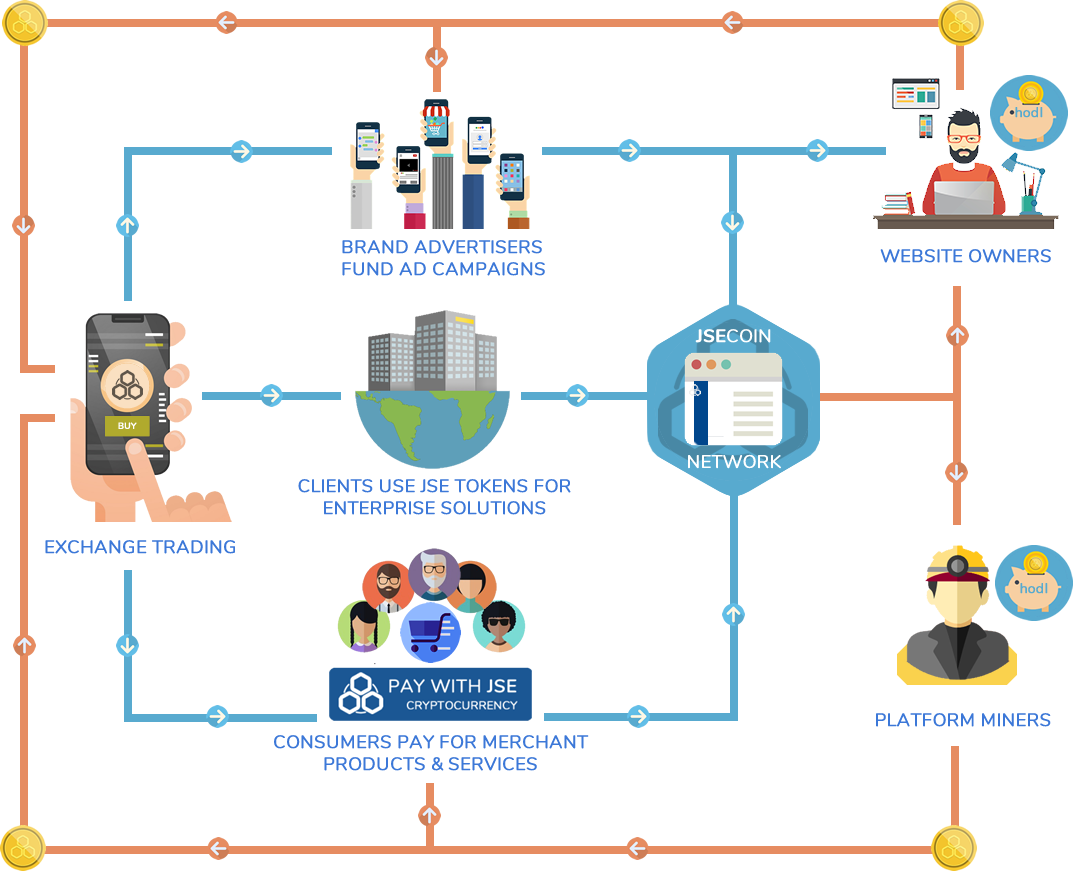
JSE ECOSYSTEM
The JSE token economy is built on digital advertising, enterprise solutions and merchant tools